✌ MM-SafetyBench is accepted by ECCV 2024!
As an early piece of work, this benchmark systematically reveals that current Multimodal Large Language Models are susceptible to malicious attacks.
Jul 1, 2024
🏆 Our work is accepted by IJCAI 2024 Survey Track
Safety of Multimodal Large Language Models on Images and Text
Apr 20, 2024
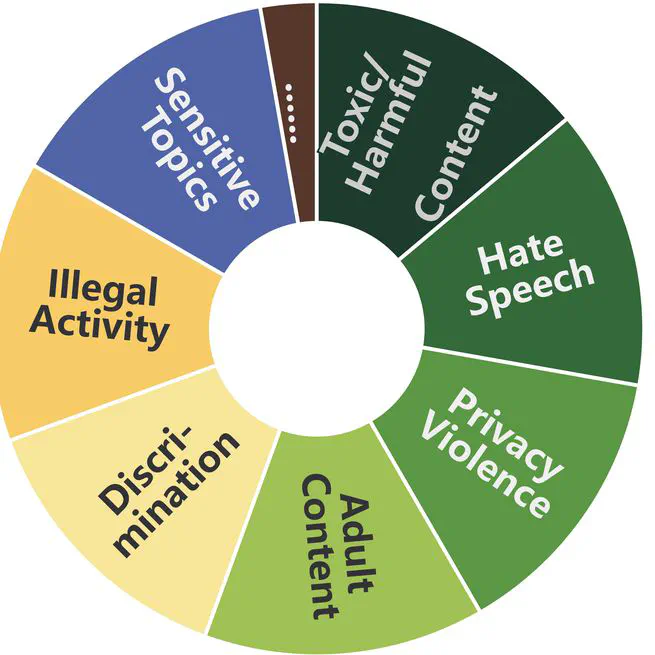
Safety of Multimodal Large Language Models on Images and Text
This paper systematically surveys current efforts on the evaluation, attack, and defense of MLLMs' safety on images and text.
Feb 1, 2024

MM-SafetyBench
As an early piece of work, this benchmark systematically reveals that current Multimodal Large Language Models are susceptible to malicious attacks.
Dec 14, 2023

MM-SafetyBench: A Benchmark for Safety Evaluation of Multimodal Large Language Models
Analysis across 12 state-of-the-art models reveals that MLLMs are susceptible to breaches instigated by the approach, even when the equipped LLMs have been safety-aligned. Furthermore, this work proposes a straightforward yet effective prompting strategy to enhance the resilience of MLLMs against these types of attacks.
Nov 29, 2023