SFT: imitation pressure
PromptGolden traceAnswer
Canonical demonstrations can solve the supervised task, but they may keep latent modules (skills, routing mechanisms) entangled inside a single golden trace.
ICML 2026
Understanding Compositional Generalization in Language Model Reasoning
*Equal contribution · Correspondence to: lingjink@cs.cmu.edu




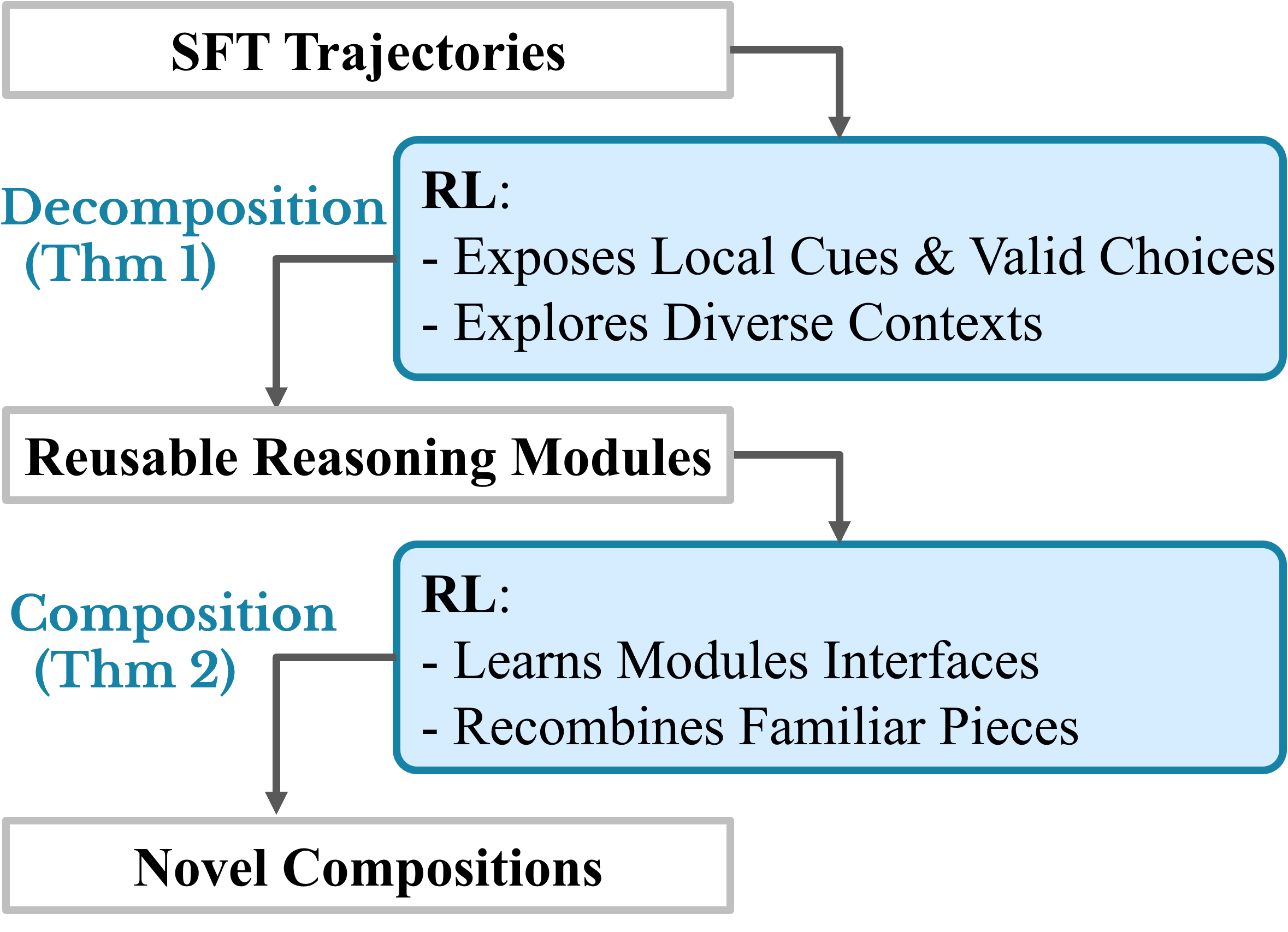
Motivation
Canonical demonstrations can solve the supervised task, but they may keep latent modules (skills, routing mechanisms) entangled inside a single golden trace.
Reward-conditioned trajectory variation exposes local cues, valid choices, and interfaces that make latent modules identifiable.
Model and theory

P induces discrete latent selections S ;
S generate the observed reasoning trace D .
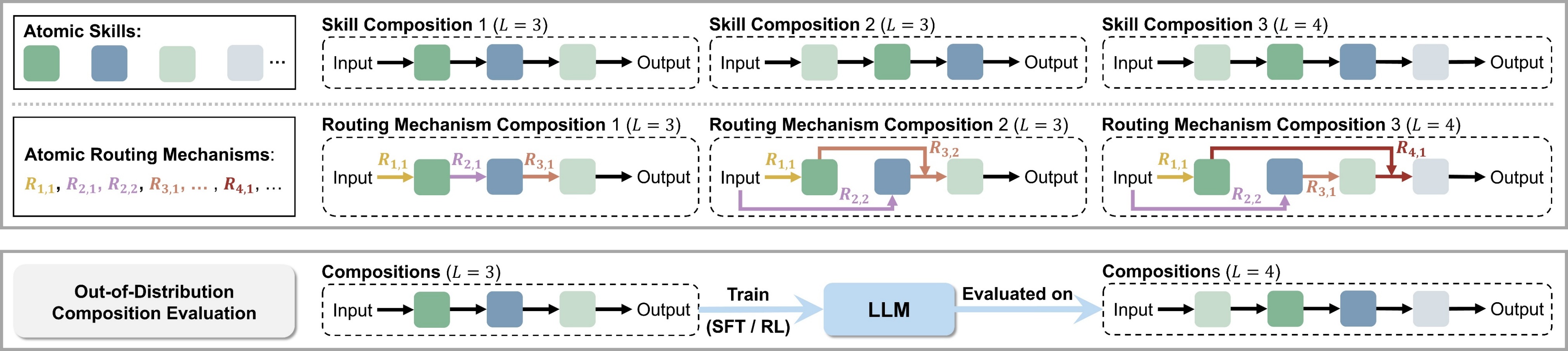
Experimental design
Synthetic tasks let us manipulate which modules and compositions are present during SFT and RL.
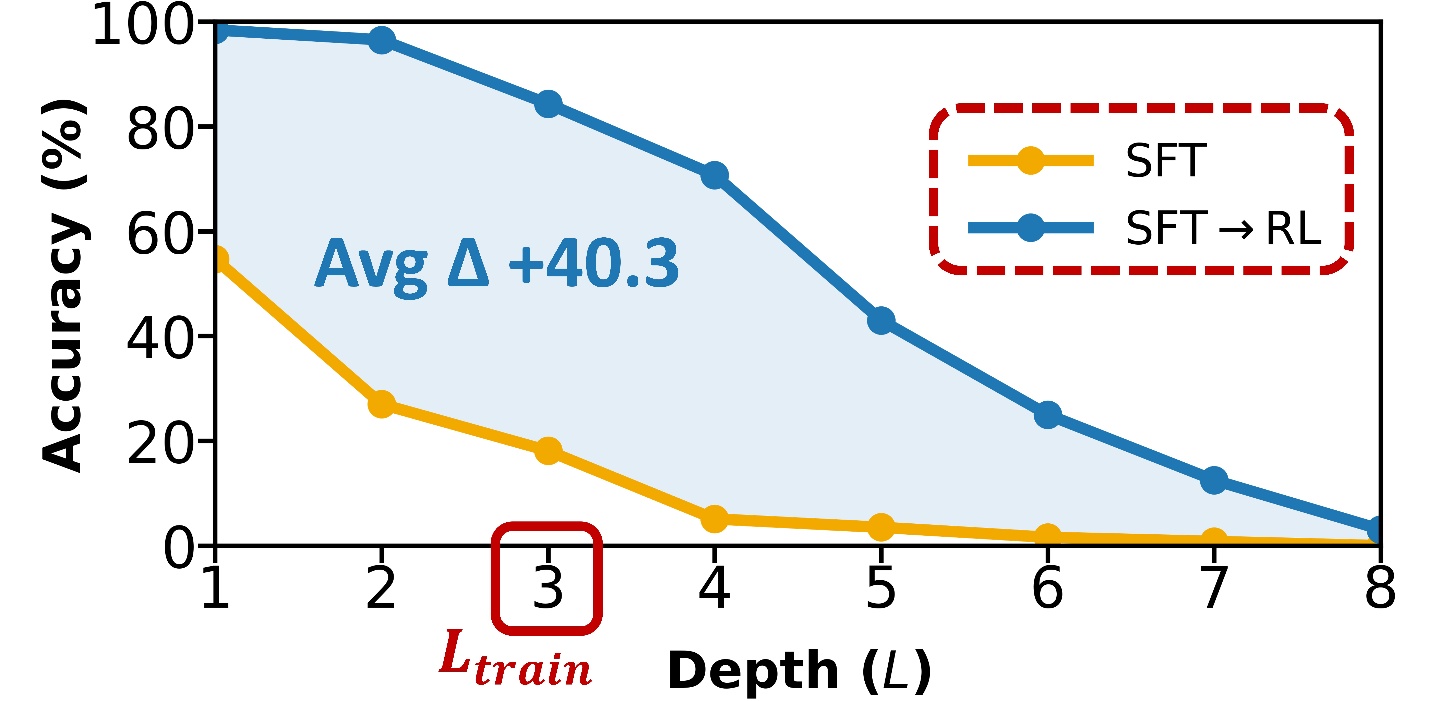
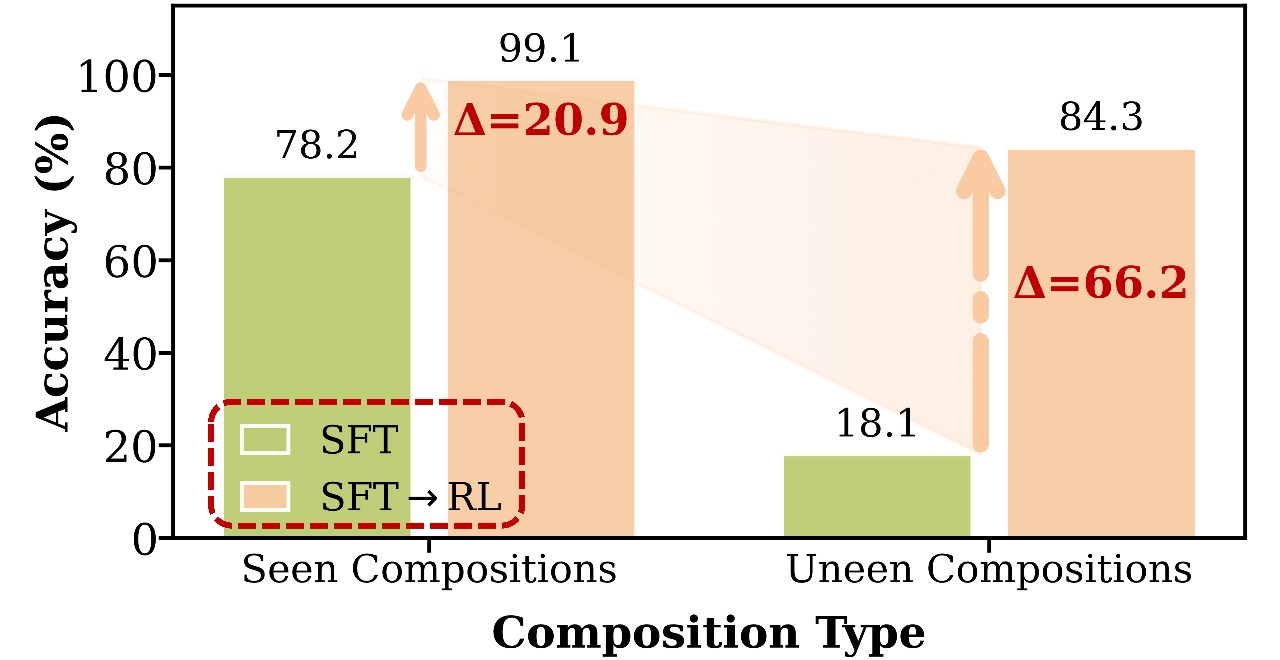
Results
Table: Average accuracy advantage of RL over SFT.
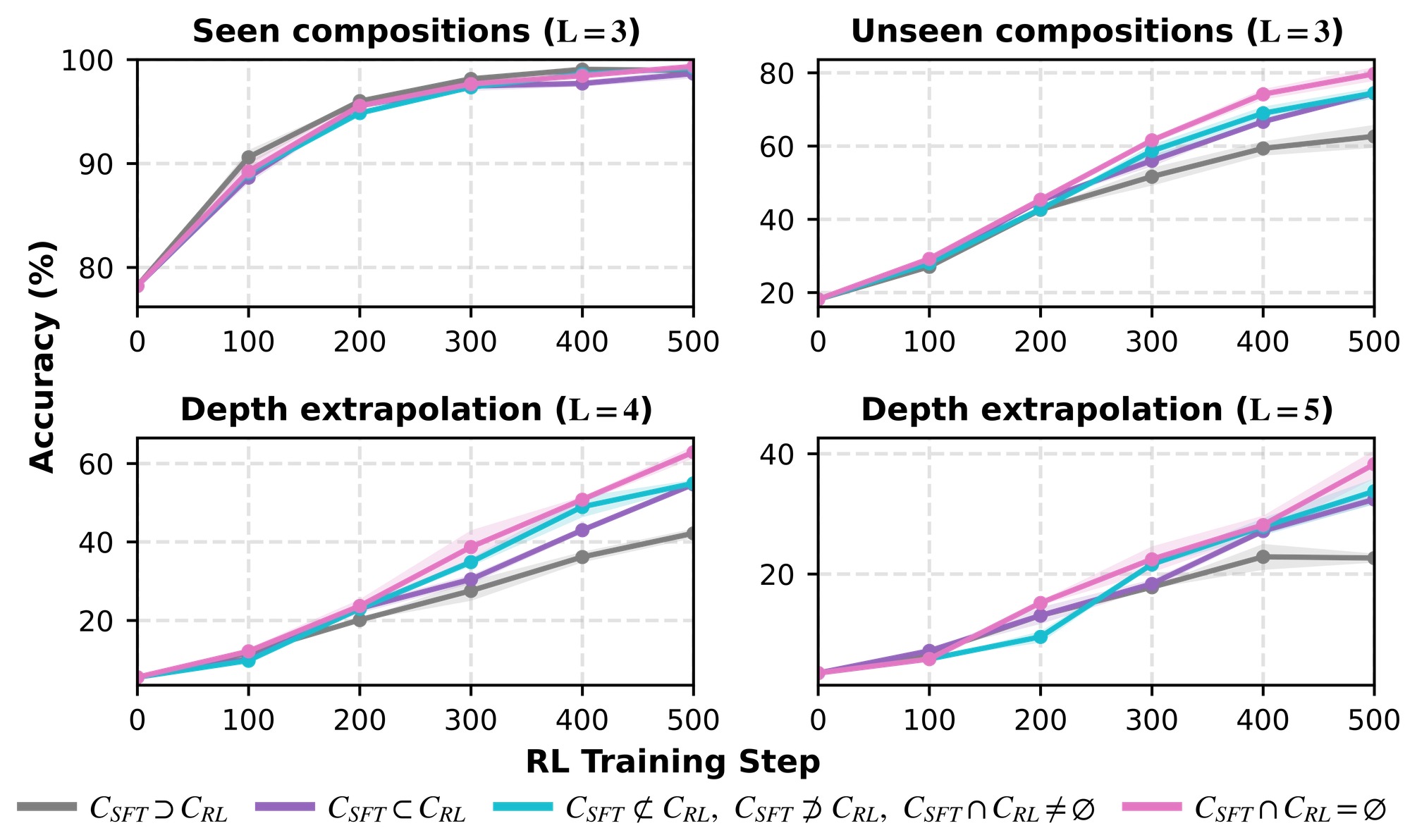
Left figure: Much larger gains on unseen than seen compositions (L=Ltrain=3).
Right figure: Effect of RL data structure on OOD compound traces (L=4).
| Training setting | Accuracy | Gain |
|---|---|---|
| SFT baseline | 4.8% | — |
| SFT + RL, atomic modules | 14.8% | +10.0 |
| SFT + RL, compound traces | 42.6% | +37.8 |
| Compound advantage | — | +27.8 |
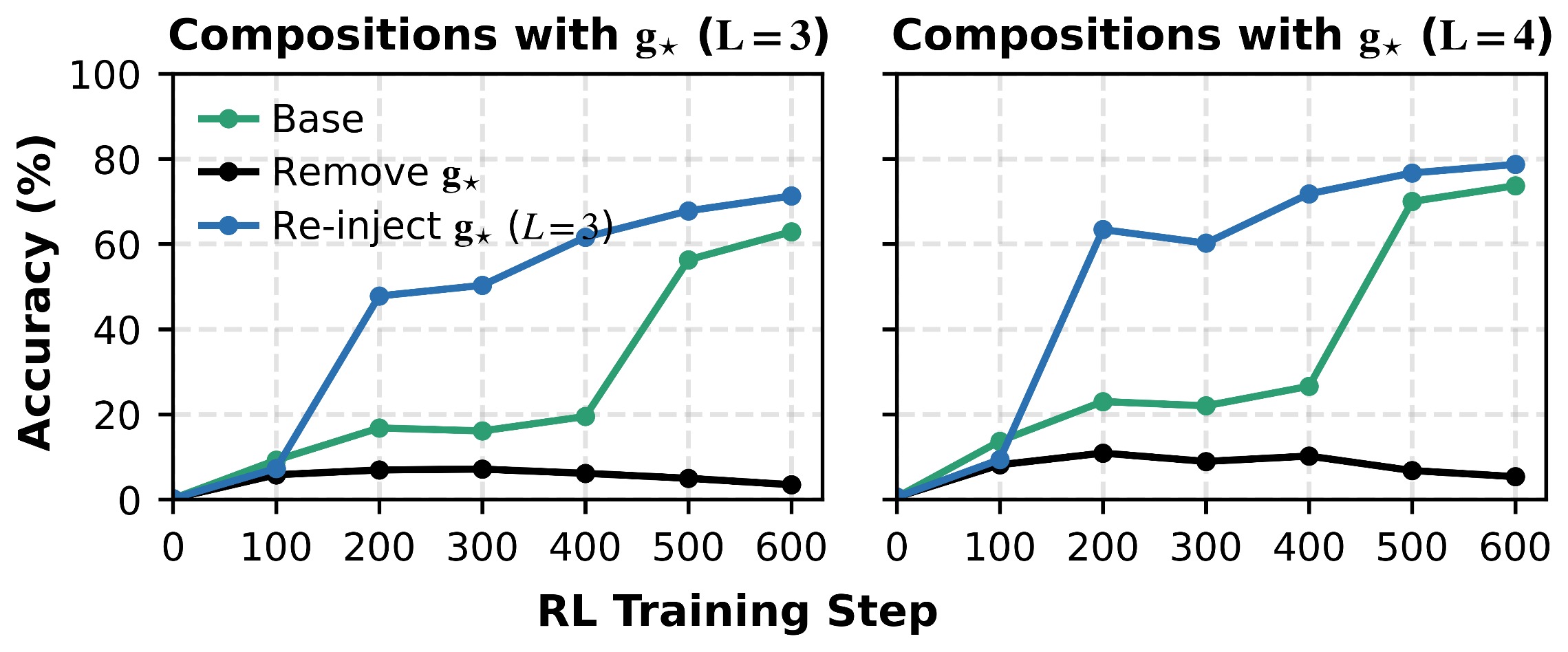
When held-out skills are reintroduced, composed examples repair generalization better than atom-only examples.
Composability is learned at interfaces: the model must see components inside composed contexts, not only in isolation.
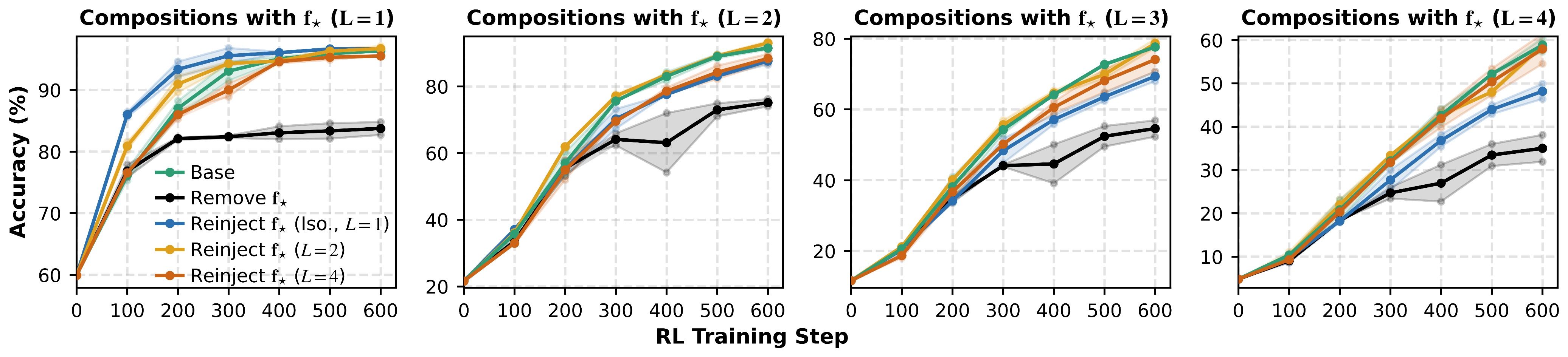
Practical connection: many reasoning failures are missing ways to connect operations, not missing operations.
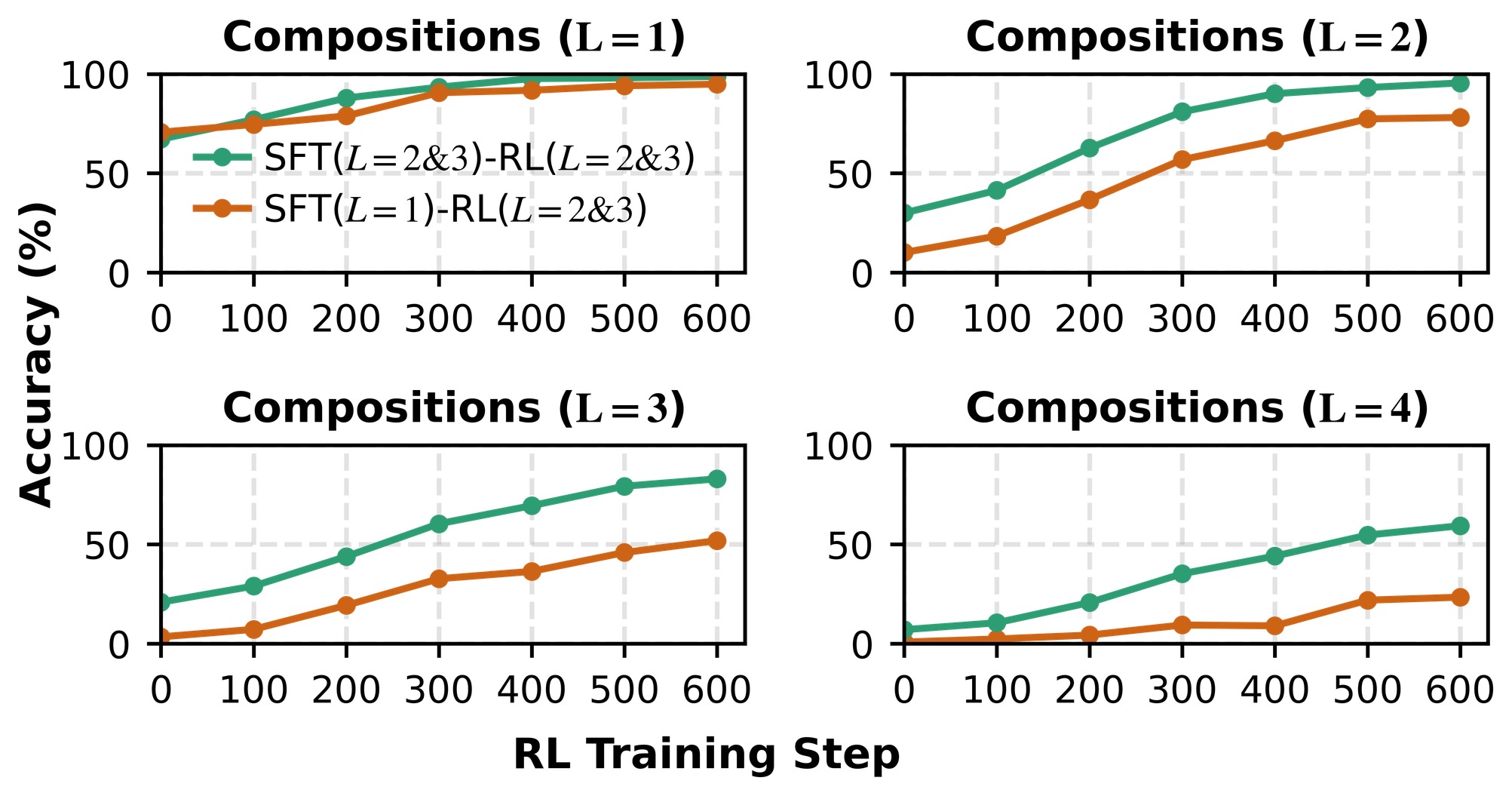
Top figure: RL works best when it explores beyond SFT support.
Bottom figure: SFT should cover the atomic inventory through compositional traces.
Citation
@misc{kong2026reasoningtracesreusablemodules,
title={From Reasoning Traces to Reusable Modules: Understanding Compositional Generalization in Language Model Reasoning},
author={Lingjing Kong and Xin Liu and Guangyi Chen and Martin Q. Ma and Xiangchen Song and Yuekai Sun and Mikhail Yurochkin and Taylor W. Killian and Ruslan Salakhutdinov and Kun Zhang and Eric P. Xing and Zhengzhong Liu},
year={2026},
eprint={2606.18089},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2606.18089},
}